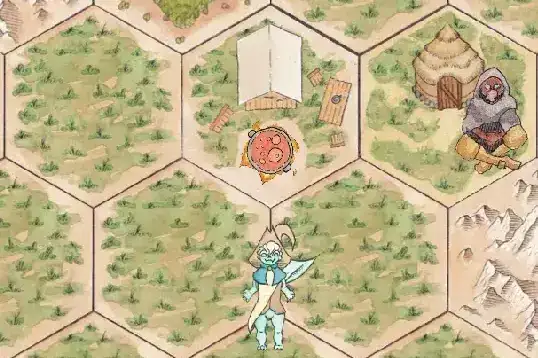
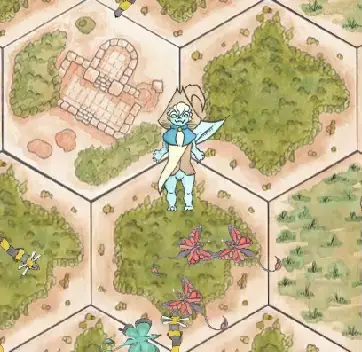
Comics im Game
Das Storytelling im Game wird neben Environmental-Storytelling auch via Cut-Scenes gezeigt. Die Cut-Scenes sind geführte Comic Szenen welche ich mit Aquarell-Farben und Tinte auf Wasserfarbepapier erstelle. Vorbereitung Ich habe in…